
Desde el tablero en blanco. Sin que nadie le enseñe. Carente de entrenamiento humano. Deep Mind, la rama de inteligencia artificial de Alphabet (matriz de Google) ha desarrollado una criatura capaz de vencer sin problema a los maestros del juego asiático go, sin haber aprendido de ellos. Es una estratega nata. AlphaGo Zero, que es como se llama, se entrenó a base de examinar sus propias jugadas contra sí misma con sólo conocer las reglas básicas del juego. Las máquinas no aprenden de los mejores. Aprenden de sí mismas para ser mejores que los humanos en estrategia.
El cine ha retratado el misterio y solemnidad en torno al go. El Dr. Silver explica la importancia de este paso para la inteligencia artificial | Vídeo: M.V., DeepMind
El go es un juego considerado una de las artes esenciales de la cultura china antigua. Cuenta con reglas simples y estrategia compleja. Dos jugadores con un conjunto de piedras cada cual, blancas y negras. El objetivo es rodear con las piedras propias un área del tablero mayor que la del oponente. Como las damas o el ajedrez, es un juego de suma cero y estrategia determinista, sólo que en el go es difícil evaluar la ventaja de la posición de una pieza. 10170 configuraciones en las posiciones del tablero, más que átomos en el universo. Por ello es ideal como reto para las máquinas.
Nuestro objetivo no es derrotar humanos. Es hacer ciencia.
Hasta hace poco, el go computerizado apenas podía ganar a los mejores humanos en tableros pequeños. Pero el año pasado AlphaGo derrotó abrumadoramente a sendos campeones de este juego. "Ahora estamos ante la versión final de AlphaGo, en que no ha necesitado interacción humana alguna para alcanzar el nivel de un maestro", asegura David Silver, el primer firmante del artículo que explica en Nature los procedimientos matemáticos y lógicos de esta inteligencia artificial.
Tal como apuntan en el artículo, "se ha avanzado mucho en la inteligencia artificial utilizando sistemas de aprendizaje supervisados, capacitados para replicar las decisiones de los expertos humanos". Sin embargo, ¿cómo poner en contacto a las máquinas con los expertos? "Los conjuntos de datos expertos suelen ser costosos, no siempre son fiables o simplemente no están disponibles", apunta Silver.
En sus experimentos han podido observar, incluso, que "AlphaGo Zero puede estar aprendiendo una estrategia que es cualitativamente diferente del juego humano". La máquina que se fijó en el conocimiento de jugadores de carne y hueso obtuvo peores resultados que la autodidacta.
La inteligencia artificial, como un árbol

Esquema de una red neuronal imaginaria
Las máquinas ven un juego como un árbol. Simplificando, de cada nudo salen dos ramas, que son las posibles decisiones o caminos a tomar. Por cada una de estas ramas brotan frutos, que son las posibles reacciones del contrincante. Según por donde haya salido el fruto, así brotarán otras dos ramas. Follaje y frutos compiten por un objetivo: alcanzar la luz del sol.
Obviamente, ni todas las ramas son tan frondosas, ni todos los frutos tan comprometedores para éstas. Digamos que la máquina puntúa cada juagada (ramas/frutos). Mirar el árbol en su conjunto, de abajo a arriba, nos daría una visión de cuál es el recorrido óptimo para alcanzar el sol. Pero eso lleva tiempo. Por ello se pueden podar algunas ramas con sus frutos, dejándolo más estrecho.
Las redes neuronales son como jardineros con experiencia. Pueden aprender qué ramas son típicamente las que más alto llegan o las que darán más fruto. La experiencia le hace puntuar a las ramas en función de si son más productivas o frondosas y así ayudan a tomar decisiones de por dónde podar.
La máquina que se anticipa a sus movimientos
Otra de las aportaciones de AlphaGo Zero es que "utiliza una sola red neuronal, en lugar de redes separadas de políticas (reglas para hacer un movimiento) y valores (para predecir lo ventajoso de una posición). Finalmente, utiliza una búsqueda de árbol más simple que se basa en esta sola red neuronal para evaluar posiciones y movimientos de muestra".
Las redes neuronales pueden aprender con supervisión humana, sin ella o por refuerzo (ensayo y error). Pues bien, AlphaGo Zero usa los dos últimos. La inteligencia artificial aprende los movimientos que maximizarán sus posibilidades de ganar a través del ensayo y el error.
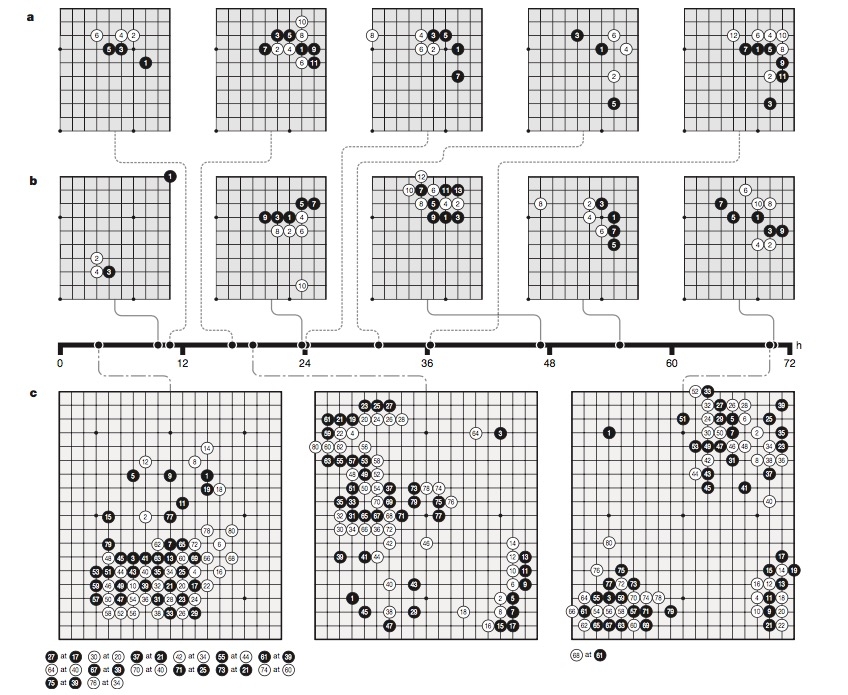
Un diagrama para personas iniciadas. Alpha Go descubrió cinco jugadas 'joseki'. A las 3h, capturaba fichas mejor que un principiante. A las 70h era una experta, haciendo jugadas 'ko'.
Empieza con unos movimientos aleatorios básicos. A partir de ahí se va dando cuenta de cuáles son los caminos que le llevarán al éxito contra sí misma. En realidad, nadie sabe cómo piensa una inteligencia artificial pues, paradójicamente, en el aprendizaje profundo no se ven paso a paso lo mecanismos últimos de decisión. Pero sí se puede ver cómo AlphaGo Zero iba prediciendo sus propios movimientos para ir acumulando estrategias.
Durante el entrenamiento, AlphaGo Zero tardaba 0,4 segundos en decidir su jugada. Combinaba simulaciones de juegos y las salidas de su red neuronal para decidir qué movimientos tenían más probabilidades de llevarle a la victoria. Luego usó esta información para actualizar su red neuronal.
Esto a los humanos nos ha llevado miles de años desde que se inventó el go. Ella lo hizo en apenas tres días, en una sola máquina provista de cuatro chips TPU.
¿Sirve esto para algo más que echar partidas de go? "En última instancia, queremos aprovechar los avances algorítmicos para ayudar a resolver todo tipo de problemas apremiantes del mundo real" asegura el cofundador de Deep Mind Demis Hassabis. Entre las posibles aplicaciones están el plegado de proteínas o el diseño de nuevos materiales. "Si podemos alcanzar el mismo progreso que con AlphaGo, podremos impulsar un nuevo conocimiento humano e impacto positivo en todas nuestras vidas", sentencia el también CEO de la compañía de inteligencia artificial. "No buscamos derrotar humanos", añade Silver. "Queremos hacer ciencia".
En todo el mundo, asociaciones de jugadores de go se reúnen para poner en común experiencias, jugadas y estrategias para ser mejores. Está por ver si AlphaGo Zero está por compartirlas o, si quiera, ella misma sabe cómo lo hace para ser imbatible.
Te puede interesar




Lo más visto
- 1 El Gobierno aprueba la nueva ayuda de 200 euros para la crianza
- 2 Carmen Asecas, Catalina en La Promesa, habla de su origen real
- 3 El novio de Ayuso aporta un correo al Supremo en el que el PSOE distribuía un “argumentario” contra él
- 4 Memento Mori vuelve hoy a Prime Video con su temporada 2
- 5 Sánchez ordena a Interior la ruptura unilateral del contrato de balas con Israel y cierra la crisis con Sumar
- 6 La cabeza de Marlaska no corre peligro
- 7 Óscar Puente a los senadores del PP: "No me busquen"
- 8 Estos son los posibles sucesores del Papa Francisco
- 9 González Amador sólo ha formalizado la demanda contra la vicepresidenta Montero